
Making Deep Neural Networks Robust To Label Noise A Loss Correction Approach
개요
논문은 Noisy Label 환경에서 딥뉴럴넷을 잘 학습시키는 방법에 대한 논문입니다. 많은 Noisy Label을 다루는 논문이 있지만, 적용 방법도 쉽고 성능도 괜찮게 내는 방법 중 하나라고 생각됩니다.
CVPR 2017에 나왔던 논문인데 현재 나오는 Noisy label관련된 논문에도 종종 비교대상 알고리즘으로 언급되는 논문이라 관심있게 보았던 논문입니다.
논문은 데이터셋에 포함된 Noise 정보 Label Transition Matrix를 알고있다는 가정하에, 이를 이용해서 Cross Entropy loss의 최적화 방향을 True label방향으로 살짝 바꾸어줍니다. 여기서 Label Transition Matrix란 클래스 개수가 일때, x 크기의 Matrix이며, 는 라벨1이 라벨2로 바뀌어있을 확률을 나타내는 행렬입니다. 논문은 이 Transition Matrix를 중점적으로 활용하여 loss를 교정합니다.
논문은 총 3가지 내용을 얘기합니다.
- Backward Correction
- Forward Correction
- Transition Matrix Estimation 방법
Backward
Backward Correction Loss는 Cross Entropy를 통해 계산 된 loss값에, Transition Matrix의 inverse를 곱해줍니다.(Transition Matrix가 Non-singular 함을 전제로 합니다)
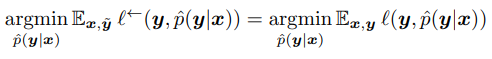
이를 논문의 Theorem 1에서 (Noise가 있는 현재 라벨)을 target으로 하는 loss에 Transition Matrix의 Inverse를 곱해준 식이 곧, (True Label)에 대한 Loss와 같다는 것을 증명해줍니다.
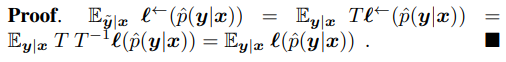
첫번째 항은 현재 있는 Noisy label에 대한 backward loss를 나타내고 있으며, 마지막 항은 실제 True Label에 대한 Loss를 나타냅니다. Label Transition Matrix 를 이용해 식이 변화하는 것을 보여주며, 이 두 항이 동일함을 증명하고 있습니다.
Forward
Forward Correction Loss는 모델이 Prediction한 예측값에 곧바로 Transition Matrix를 곱합니다. 이 역시 True Label에 대한 loss의 기대값과 forward loss의 기대값이 같음을 증명합니다.
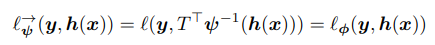
Label Transition Matrix Estimation
앞 선 두 forward와 backward 알고리즘은 Label Transition 정보를 다 알고있다는 가정하에 수행 가능 한 알고리즘 입니다. 논문에서는 이 True Label Transition을 알고있기 어려우니 이를 데이터셋에서 Estimation하는 방법을 제안합니다.
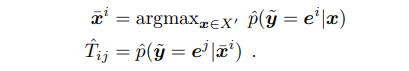
학습된 모델로 충분히 큰 특정 데이터 에 대해 estimation을 수행하는데 이 는 학습데이터 그대로 사용하여도 되고 같은 분포를 가진 데이터라면 라벨이 없는 데이터도 된다고 합니다. 특정 Class 에 대해서 가장 높은 probability를 가진 Best Sample을 선정한 후, 이 샘플이 가 아닌 다른 클래스 에 대해 가진 probability를 Noisy Ratio로 가정하고 에 이 probability를 입력합니다.
이렇게 구해진 Transition Matrix를 이용하여 위의 Forward, Backward를 수행하며 논문에서는 estimate된 를 이용한 결과와, 실제 를 이용한 결과 두가지 모두를 실험하였네요.
이 Estimation에서 어떤 모델을 써야하는지에 대한 언급을 정확히 언급된 곳을 못찾아서, 필자가 간단히 코드를 이용해 실험해본 결과, validation accuracy가 가장 높게나오는 epoch의 모델을 early stopping을 이용하여 선택하는 것이 가장 실제와 비슷한 를 구할 수 있었는데, 데이터셋 또는 실험마다 다를 순 있으니 여러 모델을 이용해서 실험해본 후 사용하여야 할 것 같습니다.
마무리
첫 리뷰로 선택된 이 Loss Correction 논문은 2017년 논문이지만 요즘에도 종종 SOTA논문에서 언급되는 알고리즘입니다. 아무래도 좋은 성능과 코드를 쉽게 짜볼수있어서 그런 것 같습니다. 논문이 수식이 많이 등장하는 논문이라, 처음에는 리뷰하기 어렵지 않을까 했으나 생각보다 쉬운 접근방법과 직관적인 수식이라 이해하기에 그렇게 어렵지 않았고, 그만큼 좋은 논문이라는 생각을 했네요. 코드도 공개되어있으니 간단한 데이터로 실험해보기도 쉬울 것 같습니다.
이번 포스팅에서 아쉬운점은 생각보다 알고리즘 부분이 짧게 설명이 된것 같아서, 다음 포스팅에서는 그림과 함께 좀더 재밋고 깊이있게 리뷰를 해보겠습니다. 읽어주셔서 감사합니다 ^^